


Introduction
In the realm of concurrency, where multiple threads, and processes work to accomplish a certain task in parallel, the concept of synchronization becomes paramount as it allows achieving data consistency across all processes when these processes access a shared resource. To solve the issue of consistency, we introduced the concept of locks and mutexes (mutual exclusion), which are objects used to control access to shared resources, for which the lock holder is the only entity allowed to access and operate on the protected resource.
Nowadays, distributed systems have become widely adopted due to the big advantages they bring, from ensuring high availability, low latency and performance. But these advantages come with their challenges, and the main challenge is data consistency across the set of workers in the distributed environment so that the shared resource is protected globally.
In this blog post, where we delve into the intricacies of locking and mutexes in a distributed environment starting by reminding the concept of mutexes in a centralized environment and then moving into the different approaches to implement them.
Mutexes
A mutex, short for "mutual exclusion," is a synchronization primitive used in concurrent programming to control access to shared resources, such as variables, data structures, or critical sections of code, by multiple threads or processes. The primary goal of a mutex is to prevent simultaneous access to the shared resource, thereby avoiding data corruption, race conditions, and other concurrency-related issues.
So they act like a gatekeep, allowing only one thread or process at a time to enter the critical section in which the process can operate on that resource. The other processes that are trying to access that resource will be temporarily blocked until the mutex is released.
There are two main operations on mutexes:
Lock: Or
Acquire, when the process wants to access the shared resource, it attempts to acquire the mutex's lock. If the mutex is currently unlocked, the requesting process gains ownership of the mutex and can process to the critical section and operate on the protected resource like writing to a file etc.Unlock: Or
Release, once the process holding the lock has finished, it releases the mutex, allowing other waiting processes o acquire the lock and access the resource.
Distributed mutexes
The challenge of distributed mutexes relies on how to keep the different servers in sync and be aware of the held locks or mutexes.
There exist multiple techniques and approaches to implement the distributed version of mutexes. We describe two main approaches that are widely adopted and which have proven their performance, the first one used Redis in-memory database, and the second one is using ZooKeeper.
Distributed mutexes using Redis
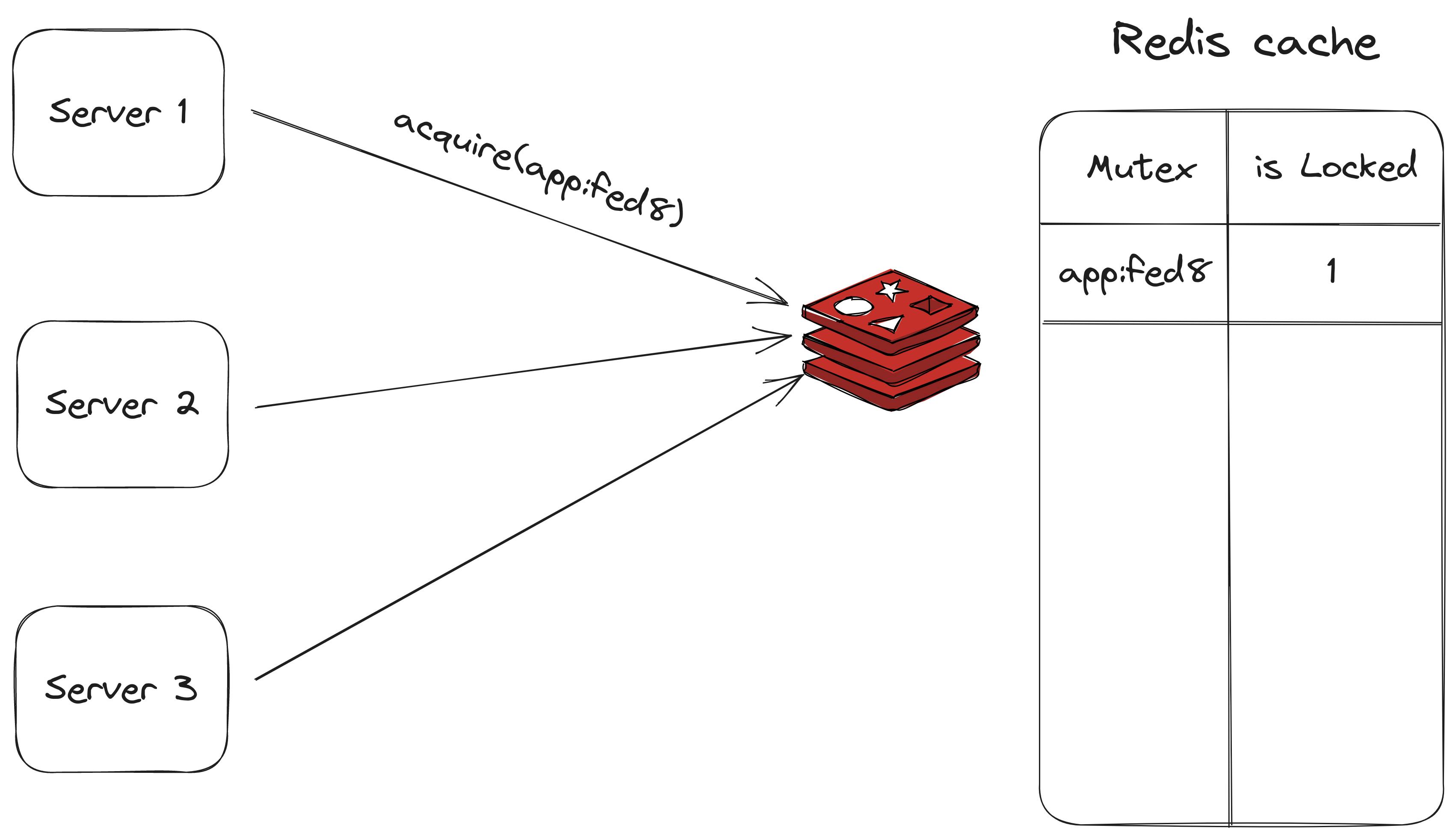
Redis cache in this architecture plays the role of a single source of truth for the different mutexes that are held. We describe the general workflow of holding and releasing the mutex.
In this section, we assume that each mutex is identified by a unique name
Acquire
To acquire the lock the server sends a
SETNXcommand, which sets a key in the database identified by the name of the mutex to 1 indicating that the mutex is held.If another server wants to acquire the mutex while the previous server is holding it, the server will be blocked and it joins the waiting list for that mutex (the server subscribes to a mutex-specific channel to receive relevant events of the mutex).
Release
Once the first server has finished its operations on the shared resource it deletes the key from the database and upon deletion it sends an event indicating that the mutex has been released.
The waiting servers will try to acquire the lock again.
This approach is good and easy enough to be implemented for large-scale distributed systems.
Actually, we started contributing to an open source named async-mutex NodeJS package which safely guards resources from the concurrent async operations. The contribution is an extension to this package for the distributed environment using the Redis adapter.
Distributed mutexes using ZooKeeper
ZooKeeper is an open-source distributed coordination service that is widely used for building and managing highly reliable, available, and scalable distributed systems. It was developed by Yahoo and later became an Apache project, maintained by the Apache Software Foundation.
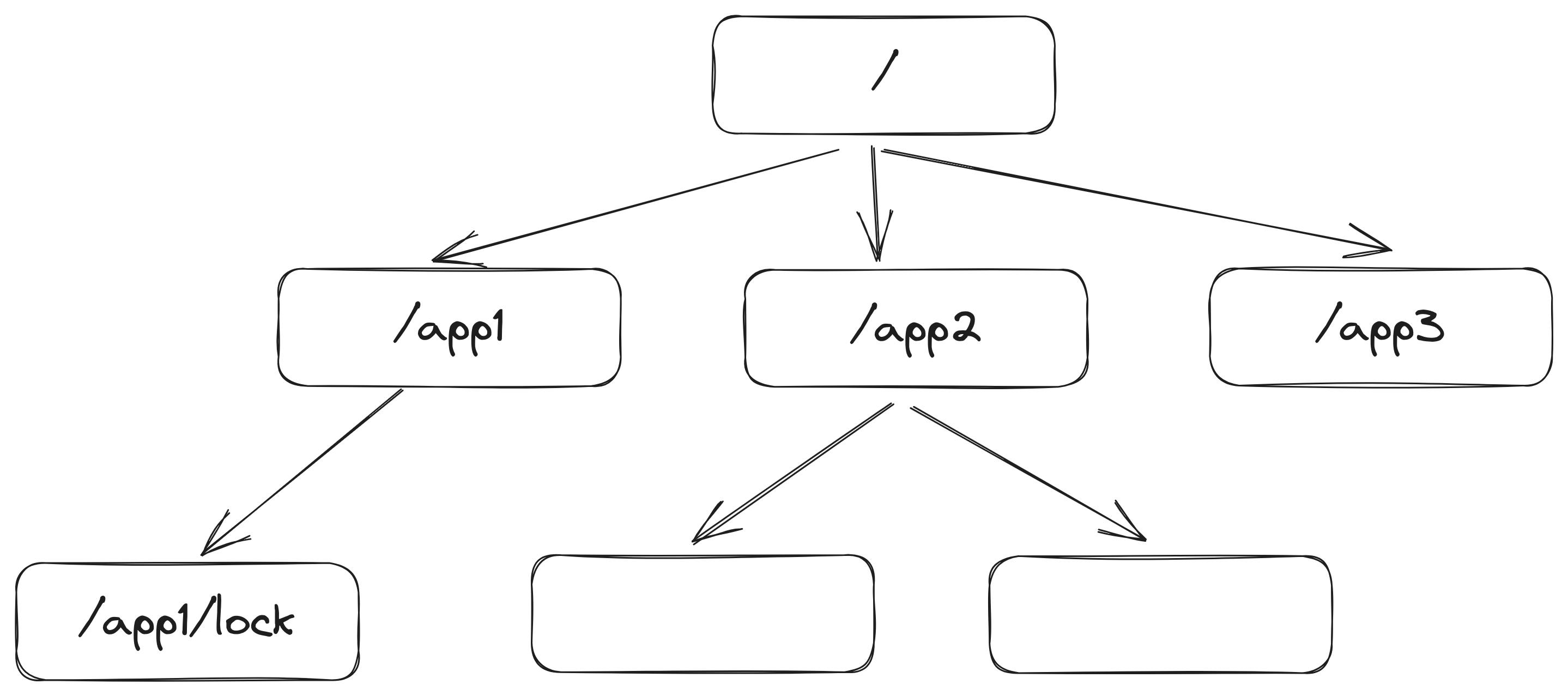
At its core, ZooKeeper provides a hierarchical and distributed data store that is optimized for coordinating and synchronizing processes in distributed environments. It offers a simple and reliable way to manage configuration information, maintain naming and synchronization services, and handle distributed locks, all of which are essential components for building complex distributed systems. (See the following figure)
The key features of ZooKeeper that are derived from the original paper are:
Hierarchical Data Model: ZooKeeper organizes data into a hierarchical namespace, similar to a file system. Each node in the hierarchy is called a "znode" and can store data as well as metadata.
Watch Mechanism: Clients can set watches on znodes to receive notifications when changes occur. This enables reactive programming and allows distributed applications to respond to changes in the distributed system's state.
Reliable and Replicated Storage: ZooKeeper achieves high availability and fault tolerance through its replication mechanism. Data is stored on multiple servers, forming a quorum, which ensures that the system can continue to function even if some servers fail.
Atomic Operations: ZooKeeper provides atomic operations for read and write operations on znodes. These operations are guaranteed to be consistent and sequential.
Leader Election: ZooKeeper can be used to elect a leader among a group of nodes, which is a fundamental building block for distributed systems like distributed databases and distributed message queues.
To use Zookeeper to implement distributed mutexes, we make use of its operations on the hierarchical data model and the watch mechanism.
We define a lock znode l to implement such locks. The approach is to line up all the clients requesting the lock and each client obtains the lock in the order of its arrival avoiding the so-called herd effect which drastically drops the performance of the system
Acquire
In order to acquire a lock, the server (zookeeper client) would do the following
// 1
n = create("l/lock-", EPHEMERAL|SEQUENTIAL);
while(true){
// 2
children = getChildren("l", false);
// 3
if n is lowes znode in children {
// Server acquired the lock
return SUCCESS;
}
// 4
p = znode in children just before n
if exists(p, true){
// Wait for zookeeper's notification
// on lock avaialability
wait()
}
}
First, we create a sequential and ephemeral lock znode under znode
l, it's ephemeral because we want the znode to be deleted upon disconnection (in case of crashes).Next, we get the list of
l's children, setting the watch to false.The only condition for which the client can hold the lock is when it has the lowest sequence number (think of it as a sequence number for a ticket in a waiting line).
Finally, we need to find the znode holding the sequence number just before ours and wait for it to hold the lock.
Release
Lock release is simply done by deleting the znode with n. Zookeeper will notify the waiting client for that znode.
delete(n)
The removal of a znode only causes one client to wake up, since each znode is watched by exactly one other client, so we do not have the herd effect.
Using Zookeeper we can monitor the locking hierarchy and see the amount of lock contention, break locks, and debug locking problems.
Conclusion
In conclusion, we talked about the need for distributed locks in a distributed environment. Next, we explained the different approaches to implementing them using Redis and Zookeeper. We notice that all of the proposed approaches rely on even-driven architecture which is considered an essential architectural paradigm in modern high-performant and scalable systems.