


Introduction
API design refers to the process of developing application programming interfaces (APIs) that expose data and application functionality for use by developers and users.
There are many different ways to develop such an API, we can use SOAP, REST, GraphQL, gRPC and others. Besides the various ways of developing APIs, we must decide which technology we should pick.
REST is the most widely used technique for developing APIs, it simply defines a set of endpoints in order to access various resources in the backend.
When a client's request is made via a RESTful API, it transfers a representation of the state of the resource to the requester or endpoint.
This information, or representation, is delivered in one of several formats via HTTP: JSON (Javascript Object Notation), HTML ...
The most serious and inevitable problem with such an approach is the amount of data transferred without really consuming most of it, this problem is known as data over fetching.
GraphQL instead uses techniques to solve such a problem and other problems as well, let's go and discover it
GraphQL
GraphQL is a specification for a new type of API design developed by Facebook to solve some problems encountered by their mobile clients. The amazing thing that graphql should be proud of is that it solves the problem of over-fetching (reducing network bandwidth consumption) that REST or any other API encounters. It allows clients to request only what they need via a query language interface. It also allows access to multiple resources in a single request, reducing the number of network calls. Additionally, it has an amazing feature for real-time data access using graphql subscriptions.
So GraphQL is all about seeing your data as a graph and then querying that graph. It allows you to precisely define the schema of the data you are making available, and then gives you a powerful query interface to navigate, traverse, and discover what you need.
GraphQL concepts
GraphQL is based on 5 main concepts:
- Schema
- Query
- Mutations
- Resolvers
- Subscriptions
Let's explore them one by one
Schema
We can think of it as the data layout or the shape of resources that the backend exposes. In the schema, we define the data that we provide and its shape so clients know how to request it.Query
A GraphQL query is used to read or fetch values from the backend server
Mutations
Mutations are like queries but they are intended to mutate (add, change or delete) data in the backend.
To achieve querying the data or mutating it we rely on graphql resolvers.
Resolvers
GraphQL resolvers are just functions to be executed by the graphql engine to make data available for clients.
One last operation is a subscription
Subscriptions
Like queries, subscriptions enable you to fetch data. But they are long-lasting operations that can change their result over time. They can maintain an active connection to your GraphQL server (most commonly via WebSocket), enabling the server to push updates to the subscription's result.
Here's an example of a graphql query which fetches a GitHub user's info
query ($user:String) {
user(login: $user){
login
name
bio
avatarUrl
followers {
totalCount
}
following{
totalCount
}
repositories{
totalCount
}
location
twitterUsername
company
websiteUrl
}
}
We can easily see that we request just what we want instead of parsing that long JSON data.
Now that we have defined what graphql is and we've seen its core concepts, we’ll head over to building our own graphql server using node js and apollo server.
We will build a tiny service name contents service which belongs let’s say to a big and complex blogging system. This service has two models, Users and Posts
Each user can have multiple posts
Server setup
We will be using the Apollo server, you can check the official documentation for an installation guide
In our main app.js
// 1
const express = require("express")
const {ApolloServer} = require("apollo-server-express")
const mongoose = require("mongoose");
const models = require("./models/index")
const utils = require("./utils")
// 2
const app = express()
mongoose.connect(process.env.MONGO_URL, {
useNewUrlParser: true
}).then(() => {
console.log("Connected to db")
}).catch(e => {
console.error(e)
process.exit(1)
})
// 3
const server = new ApolloServer({
typeDefs: schema,
resolvers,
context: {
me: utils.getLoggedInUser()
models
},
})
// 4
server.start()
.then(r => {
server.applyMiddleware({
app,
path: "/graphql"
})
app.listen({port: 8000}, () => {
console.log('Apollo Server on port 8000')
})
})
.catch((e) => {
console.error(`Could not start graphql server ${e}`)
})
- Importing the
expresslibrary along with theApolloServerserver which is based onexpress - Creating an
expressapp and connecting the database since we will be connecting resolver functions to database operations - Creating
ApolloServerinstance taking into account thetypeDefswhich are the schema from our domain, theresolversand the context which is an extra parameter passed down to resolver functions to have more fine-grained control - Starting the
graphqlserver
Schema setup
A GraphQL schema is defined by its types, the relationships between the types, and their structure. Therefore GraphQL uses a Schema Definition Language (SDL).
However, the schema doesn’t define where the data comes from. This responsibility is handled by resolvers outside of the SDL.
In our example we expose these queries to clients:
me: The client can query this field to get the currently logged-in useruser(id: ID): User: Allows to get a user by id which is a passed argument to thegraphqlquery Note that we can define our own types ingraphql(UserandPost),graphqlhas builtin types which you can check out in their official docusers: Get all userpost(id: ID): Post: Get all posts by idposts: Get all posts
All these fields reside under the Query type which is a mandatory first top-level type.
const schema = gql`
type Query{
me: User, # The currently logged-ing user
user(id: ID): User, # get user by id
users: [User]!, # Get all users
posts: [Post], # Get all posts,
post(id: ID): Post
}
type User{
id: ID!,
username: String!,
email: String!,
posts: [Post]
}
type Post{
title: String!,
text: String!,
author: User!
}
`
Now that we’ve defined our schema, let’s write the resolvers to return data!
Resolvers
As we discussed earlier, resolvers are just functions called by the graphql engine to get data.
In JavaScript, the resolvers are grouped in a JavaScript object, often called a resolver map.
Each top-level query in your Query type has to have a resolver. Now, we’ll resolve things on a per-field level.
const userResolvers = {
Query: {
me: async (parent, args, {models, me}) => {
return models.User.findById(me.id).exec()
},
user: async (parent, {id}, {models}) => {
return await models.User.findById(id).exec()
},
users: async (parent, args, {models}) => {
return await models.User.find().exec()
},
},
User: {
posts: async (user, args, {models}) => {
return await models.Post.find({
author: user.id
}).exec()
}
}
}
Each type definition from schema is mapped to a resolver key which defines functions to resolve each field.
resolver function skeleton is as follows:
parentwhich points to the previously resolved field before reaching this oneargsa JavaScript object specified the passed arguments defined by the schema- a third parameter which is the context defined once we instantiated the
Apolloserver
In our example we resolve:
mefield to get the currently logged-in userusers and userCalling mongoose ORM function- We resolve the
postsfield in theUserschema underUserin the resolver map.
const postResolvers = {
Query: {
posts: async (parent, args, { models }) => {
return await models.Post.find({}).exec();
},
post: async (parent, { id }, { models }) => {
return await models.Post.findById(id).exec();
},
},
Post: {
author: async (post, args, { models }) => {
return await models.User.findById(post.author).exec();
},
},
};
Similarly, we resolve the necessary fields for posts
Now that we have a functional API we can try it, but before that, we need to populate our database first
I’ve created two collections users and posts collections, users collection contains two users and the posts collection contains one post
Let's run the server and open up graphql studio which is a web UI client for graphql (just like postman for rest, although postman has an integrated graphql client as well we will be using the studio for a better experience )
To get all users we type the following query
query{
users {
email,
id,
username
}
}
The result would be
{
"data": {
"users": [
{
"email": "mohammed@esi.dz",
"id": "6301bba8aaf6b977104276fe",
"username": "mohammed"
},
{
"email": "andy@cmu.com",
"id": "6305037e46a91c10eeee9958",
"username": "Andy"
}
]
}
}
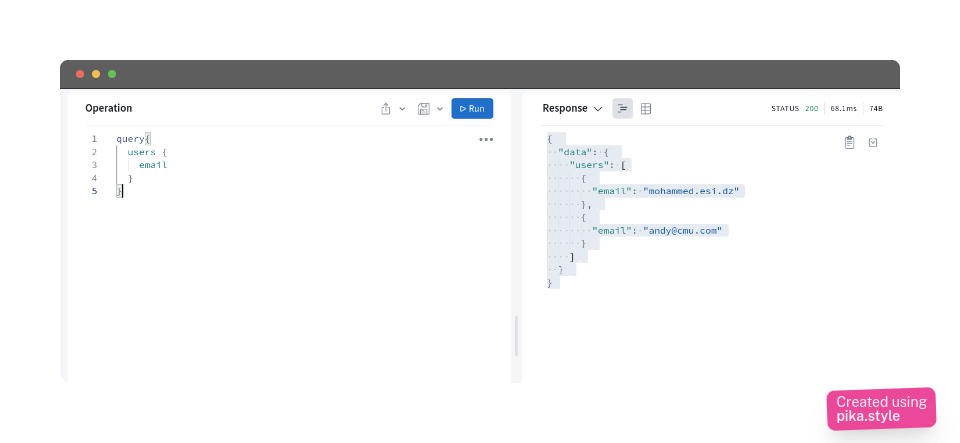
if we want just the email, we suppress the id and username fields from the query like this
query{
users {
email
}
}
And the result would be
{
"data": {
"users": [
{
"email": "mohammed@esi.dz"
},
{
"email": "andy@cmu.com"
}
]
}
}
Let's go through what happened.
When we query the users field, the graphql engine would call the users resolver function defined earlier to get the data, but if we have a complex query with nested fields and all of these fields should be resolved, it will build a tree of nodes to resolved and recursively call the resolver functions.
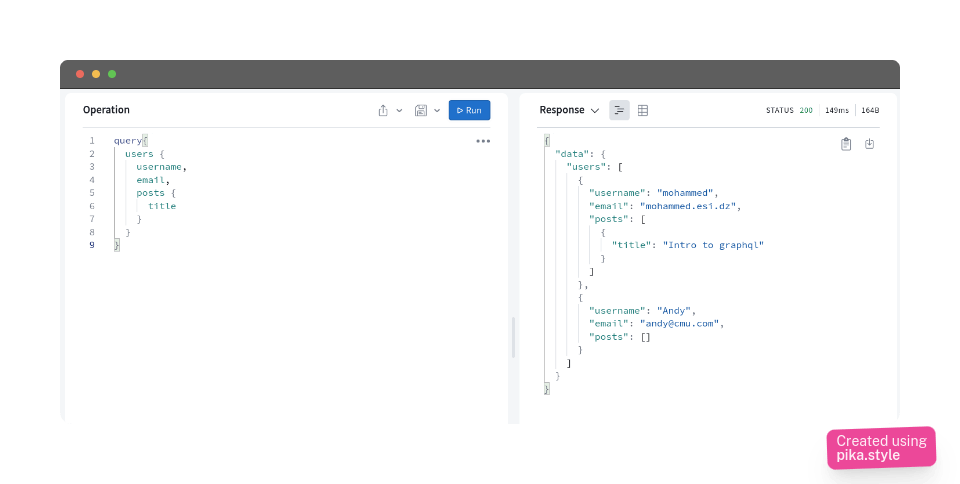
Here’s another example of fetching users along with their posts
query{
users {
username,
email,
posts {
title
}
}
}
And here’s what we get
{
"data": {
"users": [
{
"username": "mohammed",
"email": "mohammed@esi.dz",
"posts": [
{
"title": "Intro to graphql"
}
]
},
{
"username": "Andy",
"email": "andy@cmu.com",
"posts": []
}
]
}
}
Mutations
In a nutshell, mutations allow altering data (update or deletion) in order to have a complete CRUD API
Let’s see how they can be defined and applied to our example.
A mutation type definition is just like a queries type definition but most of the fields take arguments holding the data.
We define two mutations, createPost, deletePost.
Functions behaviour is self-explanatory so we can go ahead and see the resolvers for those fields.
Mutation: {
createPost: async (parent, { title, text, author }, { models }) => {
const post = await models.Post.create({
title: title,
text: text,
author: author,
});
return post
},
deletePost: async (parent, { id }, { models }) => {
return await models.Post.deleteOne({
_id: id
}).exec();
},
},
When the client requests a post creation, the createPost function will be triggered by the graphql engine just like queries
Here’s a demo to showcase mutations
mutation{
createPost(
title: "Intro to db",
text: "...",
author: "6305037e46a91c10eeee9958"
) {
title
author {
username
}
}
}
and here’s the result
{
"data": {
"createPost": {
"title": "Intro to db",
"author": {
"username": "Andy"
}
}
}
}
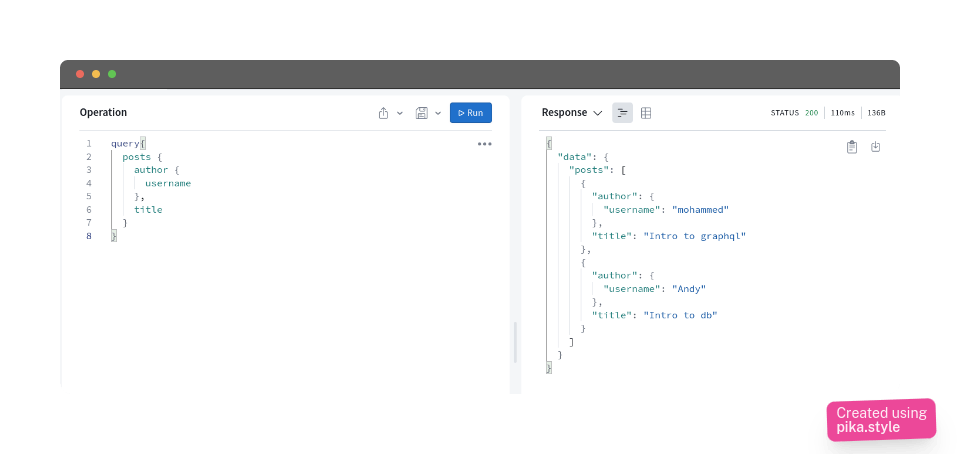
if we query all posts we get the new post by Andy
query{
posts {
author {
username
},
title
}
}
{
"data": {
"posts": [
{
"author": {
"username": "mohammed"
},
"title": "Intro to graphql"
},
{
"author": {
"username": "Andy"
},
"title": "Intro to db"
}
]
}
}
Something to be noted is that instead of placing arguments values directly into query parameters we can define variables and pass them, I’ll refer to their documentation for more details.
With this we finish our discussion about graphql API design, there’s a lot to explore about it.
In my next post, I’ll talk about real-time communication in software engineering and I’ll go through the last concept of graphql which is Subscriptions so stay tuned!
Yaay! you just finished reading my first blog post I hope you enjoyed reading it.
If you have anything to discuss about this topic feel free to reach me :)